IDEF1X
IDEF1X (Integration DEFinition for information modeling) は、セマンティックデータモデルを開発するためのモデリング言語である。環境やシステムにおける情報の構造と意味を表現する図式情報モデルを作成するのに使われる[1]。

IDEF1Xにより、資源としてのデータ管理、情報システムの統合、およびデータベースの構築を支援するようなセマンティックデータモデルの構築が可能になる。IDEF1Xは、ソフトウェア工学の分野におけるモデリング言語であるIDEFファミリの一部である。
アメリカ国立標準技術研究所 (NIST) の FIPS 184 として標準化されていたが、2008年9月2日をもって廃止された[2]。
概要 編集
データモデリングの手法は、データを資源(リソース)として管理する目的で、標準的で一貫した予測可能な手法によってデータをモデル化するのに使われる。これは、組織内のデータ資源を定義・分析する標準的手段が必要なプロジェクトにおいて使われうる。このようなプロジェクトには、データモデリング手法の方法論への組み込み、資源としてのデータ管理、情報システムの統合、あるいはデータベースの設計が含まれる。IDEF1X標準の主な目的は、以下のものを提供することである[1]。
- 組織におけるデータ資源を完全に理解し、分析するための手段
- データの複雑さを表現・伝達する共通手段
- 事業体の運営に必要となるデータの全体的なビューを提示する手法
- ユーザーが検証可能かつ物理データベース設計に変換可能な、アプリケーションから独立したデータのビューを定義する手段
- 既存のデータ資源を元に、統合化されたデータ定義を導出する手法
IDEF1Xの主要な目的は、システムインテグレーションを支援することにある。そのための手段として、「概念スキーマ」と呼ばれるデータ資源の単一の意味定義を獲得・管理・使用することに焦点を合わせている。概念スキーマは、特定のアプリケーションへの偏りがなく、データの物理的な保存手段やアクセス手段から独立な、事業体における単一の統合化されたデータ定義を提供する。この概念スキーマの主な目的は、データの完全性 (integrity) を統合・共有・管理するために使われうるデータの、その意味と相互関係について、一貫した定義を提供することである。概念スキーマは、以下の3つの重要な特性を持っていなければならない[1]。
- 事業基盤に整合しており、全ての応用領域にわたって真であること。
- 拡張可能であり、既存のデータ定義を変更せずに新たなデータを定義できること。
- 要求されるユーザー・ビュー、あるいは種々のデータストレージとアクセス構造の、いずれにも変換可能であること。
歴史 編集
IDEFの開発 編集
セマンティックデータモデルの必要性が最初に認識されたのは、1970年代半ばの米空軍によるICAM(統合コンピュータ支援製造)プログラムにおいてであった。このプログラムは、コンピュータ技術を体系的に適用することで製造の生産性を向上させることを目的とした。ICAMプログラムの結果、製造の生産性向上のためには、分析とコミュニケーションの技術を改善する必要性があることが認識された。その結果、ICAMプログラムによってIDEF (ICAM Definition) メソッドとして知られる以下の一連の手法が開発された[1] 。
- IDEF0 : 環境やシステムにおけるアクティビティやプロセスを構造化して表現する「機能モデル」の作成に使用
- IDEF1 : 環境やシステムにおける情報の構造と意味を表現する「情報モデル」の作成に使用
- IDEF2 : 「動的モデル」の作成に使用
IDEF1と情報モデリング 編集
IDEFの情報モデリング (IDEF1) については、当時の研究と業界のニーズに基づき、1981年にICAMプログラムによって最初のアプローチが発表された。このアプローチの理論的背景は、関係モデル におけるエドガー・F・コッド と実体関連モデルにおけるピーター・チェンの初期の研究に由来した。初期のIDEF1手法は、チャールズ・バックマン、ピーター・チェン、M・A・メルカノフ、G・M・ネイッセンによる厳しい批評と影響の下における、ヒューズ・エアクラフトのR・R・ブラウンとT・L・レイミー、D. Appleton Company (DACOM) のD・S・コールマンによる成果を基礎とした[1]。
1983年、米空軍はICAMプログラムの下に統合情報支援システム (IISS) プロジェクトを立ち上げた。このプロジェクトは、異種のハードウェアおよびソフトウェアのネットワークを論理的かつ物理的に統合する技術を開発することを目的とした。このプロジェクトの結果と、さらには業界における経験から、情報モデリングのための高度な技術の必要性が認識されるようになった[1]。
IDEF1XとLDDT 編集
IDEF1Xとは、空軍のIDEFプログラムの管理者の観点から見るならば、ICAM IISS-6201プロジェクトの成果であり、ICAM IISS-6202プロジェクトによってさらに拡張されたものである。IISS-6202プロジェクトにおいて認識されたデータモデリングの拡張要求を満たすため、下請業者であったDACOMは、論理データベース設計技術 (LDDT, Logical Database Design Technique) とそのサポートソフトウェア (ADAM) のライセンスを取得した。IDEF1Xは、モデリング手法の技術内容の観点から見るならば、単にLDDTを改名したものである。
LDDTは、データベース設計グループ (The Database Design Group) のロバート・G・ブラウンによって1982年に開発された。彼らはIDEFプログラムとはまったく無関係であり、IDEF1についての知識はなかったが、しかしIDEF1とLDDTの核心的な目標は同じであった。すなわち、関連する実世界のエンティティをモデル化し、事業体に必要な永続的な情報について、データベースに依存しないモデルを作成することである。LDDTでは、データのモデル化とデータモデルのデータベース設計への変換を支援するため、関係データモデルである実体関連モデルにデータの汎化という要素を組み合わせた。
LDDTには、階層化環境(名前空間)、多層モデル、汎化・特化のモデリング、主キーおよび外部キー関係の明示的表現が含まれた。最終的に設計されるデータベースがどのような種類であろうとも、時に微妙なケースのある一意性と参照整合性の制約は認知、遵守されなければならないが、LDDTではこれを主キーと一義的な役割名の外部キーによって表現した。これはデータベース設計においてキーやインデックスにLDDTモデルに基づく制約を使うかどうかとはまったく別である。モデルを比較的スムーズにデータベース設計に変換するにあたって、LDDTモデルの精度と完全性は重要な要素となった。初期のLDDTモデルはIBMの階層型データベースであるIMSのデータベース設計に変換されていたが、のちにCullinetのネットワーク型データベースであるIDMSや、様々な関係データベースのデータベース設計にも変換されることとなった。
LDDTの図式構文はIDEF1とは異なっており、しかもLDDTにはIDEF1に存在しない多くの相互関係モデリングの概念が含まれていた。そのためIDEF1を拡張することはせず、代わりにDACOMのメアリー・E・ルーミスは、LDDTの大部分について、可能な限りIDEF1と互換性のある用語を使ってその構文と意味の要約を書き上げた。 DACOMはこの成果をIDEF1Xと名付けてICAMプログラムに提供し、1985年に発表された (IEEE 1998, p. iii) (Bruce 1992, p. xii)[1]。
構成要素 編集
-
 エンティティの構文
エンティティの構文 -
 ドメインの階層構造
ドメインの階層構造 -
 属性の例
属性の例 -
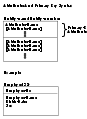 主キーの構文
主キーの構文




- エンティティ (entity)
- 実在または抽象的な「もの」(人物、オブジェクト、場所、イベント、アイデア、それらの組み合わせなど)の分類を表し、ある「もの」がそれと同じ特性や関係性を備えていることをもってそのインスタンスであると認識されるもの。
- ドメイン (domain)
- 属性が持ちうる実際の値を規定する、データ型がすべて同一の値の集合(有限個もしくは無限個)に名前を付けたもの。すべての属性は必ず1つのドメイン上に定義される。複数の属性が同じドメイン上にあっても構わない。
- 属性 (attribute)
- エンティティの一部または全部のインスタンスに共通するプロパティ。属性は、そのエンティティの文脈におけるドメインの利用を表す。
- キー (key)
- その値によってエンティティのインスタンスが一意に識別される、1つもしくは複数の属性の組。それぞれの組は候補キーを構成する。
- 主キー (primary key)
- エンティティのインスタンスの一意な識別子として選択された、一組の候補キー。
- 外部キー (foreign key)
- エンティティにおいて、関連する親エンティティの主キーとその値が一致するような、1つもしくは複数の属性の組。外部キーは、接続リレーションまたは分類リレーションを通じて親エンティティの主キーを「移行 (migration)」した結果現れるものである。外部キーの属性の組には子エンティティでの役割に基づく役割名を割り当てることができる。
-
 リレーションの多重度(カーディナリティ)の構文
リレーションの多重度(カーディナリティ)の構文 -
 依存リレーションの構文
依存リレーションの構文 -
 分類リレーションの構文
分類リレーションの構文 -
 不特定リレーションの構文
不特定リレーションの構文




- リレーション (relationship)
- 同じまたは異なる2つのエンティティのインスタンス間の関連。
- 接続リレーション (connection relationship)
- 単に関連している以上の意味をもたないリレーション。制約、多重度も参照。
- 分類リレーション (categorization relationship)
- どちらのエンティティのインスタンスも同じ実在または抽象的な「もの」を表現するリレーション 。一方のエンティティ(汎化エンティティ、generic entity)は「もの」の全体集合を表し、もう一方のエンティティ(分類エンティティ、category entity)は「もの」の下位分類を表す。分類エンティティは、汎化エンティティの全てのインスタンスが持つわけではない属性またはリレーションを持つことがある。分類エンティティのインスタンスは、同時に汎化エンティティのインスタンスである。
- 不特定リレーション (non-specific relationship)
- どちらのエンティティのインスタンスも他方に対して多の関連をもつリレーション。
- ビューレベル (view level)
- IDEF1Xでは、それぞれ抽象度の異なるビューとしてエンティティリレーション (ER, entity relationship)、キーベース(KB, key-based)、完全属性 (FA, fully attributed) の3つが定義されている。ERレベルが最も抽象度が高く、主題に関する最も基礎的な要素であるエンティティとリレーションのみをモデル化する。KBレベルではこれにキーが加わり、FAレベルでは全ての属性が追加される。
トピックス 編集
三層スキーマ 編集

ソフトウェア工学における三層スキーマは、 データ統合を達成する鍵となる概念モデルを促進するような情報システムおよびその管理を構築する手法である[4]。
スキーマとは、通常ダイアグラムによって表現され、時に文章の記述を伴うようなモデルである。この手法における三層のスキーマとは以下のものである[5]。
- ユーザー・ビューに利用される外部スキーマ
- 複数の外部スキーマを統合する概念スキーマ
- 物理ストレージ構造を定義する内部スキーマ
中間の概念スキーマは、ユーザーがそれについて考えたり、話したりするときの概念のオントロジーを定義する。内部スキーマはデータベースに保存されたデータの内部形式を表現し、外部スキーマはアプリケーションに提示されるデータのビューを定義する[6]。このフレームワークは、複数のデータモデルを外部スキーマに使用できるようを意図されたものである[7]。
モデリングの指針 編集

モデリングの過程は5つの段階に分けることができる。
- フェーズ0 - プロジェクトの開始
- このフェーズの目的は以下の通りである。
- プロジェクト定義 - 何が達成されるべきで、それはなぜか、またどのようにして達成するかの総合的な記述
- 原資料 - 索引化とファイル化を含む、原資料の入手計画
- 作成者の慣例 (Author conventions) - モデルの作成・管理における慣例(任意の方法)の基本的定義
- フェーズ1 - エンティティの定義
- このフェーズの目的は、モデル化の対象となる領域におけるエンティティを特定し、定義することである。
- フェーズ2 - リレーションの定義
- このフェーズの目的は、エンティティ間の基本的なリレーションを定義することである。この段階におけるリレーションは不特定リレーションとなる場合があり、後続のフェーズで修正が必要となる。このフェーズの主なアウトプットは以下の通りである。
- エンティティ-リレーションマトリクス
- リレーション定義
- エンティティレベル図
-
 エンティティ-リレーションマトリクス
エンティティ-リレーションマトリクス -
 エンティティレベル図
エンティティレベル図 -
 エンティティレベル図の例
エンティティレベル図の例 -
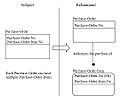
 参照図
参照図


_Diagram_Example.jpg)
.jpg)
- フェーズ3 - キーの定義
- このフェーズの目的は以下の通りである。
- フェーズ2における不特定リレーションの修正
- 各エンティティのキー属性の定義
- 主キーの移行による外部キーの確立
- リレーションとキーの妥当性検証
-
 参照図の例
参照図の例 -
 不特定リレーションの修正
不特定リレーションの修正 -
 機能的ビューのスコープ
機能的ビューのスコープ -
属性の例
-
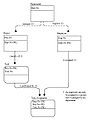
 非繰り返し規則の修正
非繰り返し規則の修正 -
 規則の修正
規則の修正 -
 パスのアサーション
パスのアサーション -
 フェーズ3の機能的ビューのダイアグラム例
フェーズ3の機能的ビューのダイアグラム例







- フェーズ4 - 属性の定義
- このフェーズの目的は以下の通りである。
- 属性集合の開発
- 属性の所有者の確立
- 非キー属性の定義
- データ構造の妥当性検証と修正
-
 非繰り返し規則の適用
非繰り返し規則の適用 -
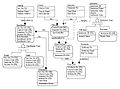 フェーズ4の機能例
フェーズ4の機能例


メタモデル 編集
メタモデルとは、モデリングシステムの構成要素のモデルである。通常のモデルと同様に、モデルの主題(この場合はIDEF1X)について、その構成要素が何であり、それらが互いにどう関連するかといった、表現、推論を行うために用いられる。このようなメタモデルは、リポジトリ設計、ツール設計、有効なIDEF1Xモデル集合の特定など、様々な用途に利用されうる。作成されるモデルは目的によっていくらか異なり、「唯一の正しいモデル」というのは存在しない。たとえばモデルを少しずつ構築することを支援するツールであれば、不完全なモデルや時には矛盾したモデルを許容しなければならない。しかし形式化のためのメタモデルであれば、形式化の概念との整合が重視されるため、不完全なモデルや矛盾したモデルは許容されない。
メタモデルには重要な制限が2つある。1つ目は、メタモデルとは構文 (syntax) を規定するものであり、意味 (semantics) を規定するものではないということ。2つ目は、自然言語または形式言語によって制約を補足しなければならないということである。IDEF1Xの形式理論では、意味と、必要な制約を正確に表す手段の両方を提供している。
IDEF1Xメタモデルは右(あるいは上)の図に示されている。ドメインの階層構造と制約も与えられており、制約はメタモデルの形式理論の文によって表現される。メタモデルは、有効なIDEF1Xモデルに対応するサンプルインスタンス表といった通常の方法によって、その集合を非形式的に定義する。メタモデルはまた、次に述べる方法によって有効なIDEF1Xモデルの集合を形式的にも定義する。メタモデルはIDEF1Xモデルとして対応する形式理論を持ち、理論の意味 (semantics) は標準的な方法で定義される。つまり、理論の解釈 (interpretation) は個体のドメインおよび以下の割り当ての集合から構成される。
- 理論における定数には、ドメイン上の個体が割り当てられる。
- 理論におけるn項関数記号には、ドメイン上のn項関数が割り当てられる。
- 理論におけるn項述語記号には、ドメイン上のn項関係が割り当てられる。
意図された解釈 (intended interpretation) において、個体のドメインはビュー(例:製造)、エンティティ(例:部品や製造者)、ドメイン(例:在庫数)、接続リレーション、カテゴリのクラスタなどから構成される。理論のすべての公理がその解釈において真であるとき、その解釈はその理論に対するモデルと呼ばれる。IDEF1Xメタモデルとその制約に対応するIDEF1Xの理論に対するモデルは、すべて有効なIDEF1Xモデルである。
関連項目 編集
脚注 編集
![]() この記事にはパブリックドメインである、アメリカ合衆国連邦政府が作成した次の文書本文を含む。アメリカ国立標準技術研究所.
この記事にはパブリックドメインである、アメリカ合衆国連邦政府が作成した次の文書本文を含む。アメリカ国立標準技術研究所.
- ^ a b c d e f g FIPS Publication 184 released of IDEF1X by the Computer Systems Laboratory of the National Institute of Standards and Technology (NIST). 21 December 1993.
- ^ Federal Register(連邦官報)vol. 73 / page 51276
- ^ itl.nist.gov (1993) Integration Definition for Information Modeling (IDEFIX). 21 Dec 1993.
- ^ STRAP SECTION 2 APPROACH. Retrieved 30 September 2008.
- ^ Mary E.S. Loomis (1987). The Database Book. p. 26.
- ^ John F. Sowa (2004). [ "The Challenge of Knowledge Soup"]. published in: Research Trends in Science, Technology and Mathematics Education. Edited by J. Ramadas & S. Chunawala, Homi Bhabha Centre, Mumbai, 2006.
- ^ Gad Ariav & James Clifford (1986). New Directions for Database Systems: Revised Versions of the Papers. New York University Graduate School of Business Administration. Center for Research on Information Systems, 1986.
参考文献 編集
- Thomas A. Bruce (1992). Designing Quality Databases With Idef1X Information Models. Dorset House Publishing.
- Y. Tina Lee & Shigeki Umeda (2000). "An IDEF1x Information Model for a Supply Chain Simulation".
- U.S. Department of Interior (2005). "Data Reference Model Overview". May 4, 2005
外部リンク 編集
- FIPS Publication 184 Announcing the IDEF1X Standard December 1993 by the Computer Systems Laboratory of the National Institute of Standards and Technology (NIST). (Withdrawn by NIST 08 Sep 02 see Withdrawn FIPS by Numerical Order Index)
- Overview of IDEF1X at www.idef.com
- IDEF1X Overview from Essential Strategies, Inc.
- IDEF1X "Cheat Sheet"