メモリオーダリング
このページは著作権侵害のおそれが指摘されており、事実関係の調査が依頼されています。
このページの現在または過去の版は、ウェブサイトや書籍などの著作物からの無断転載を含んでいるおそれが指摘されています。もしあなたが転載元などをご存知なら、どうぞこのページのノートまでご一報ください。 著作権侵害が確認されると、このページは削除の方針により一部の版または全体が削除されます。もしこのページの加筆や二次利用をお考えでしたら、この点を十分にご認識ください。 |
この項目「メモリオーダリング」は途中まで翻訳されたものです。(原文:英語版 "Memory_ordering" 13:04, 21 January 2015 (UTC)) 翻訳作業に協力して下さる方を求めています。ノートページや履歴、翻訳のガイドラインも参照してください。要約欄への翻訳情報の記入をお忘れなく。(2015年2月) |
メモリオーダリング(英: Memory Ordering)とは、CPUによるコンピュータメモリへのアクセス順序を表わす。この言葉は、コンパイル時のコンパイラに生成されるメモリオーダリングか、実行時にCPUによって生成されるメモリオーダリングのいずれかを指す。
近代的なマイクロプロセッサでは、メモリオーダリングはメモリ操作の順番を入れ替えるCPUの特性を示す。メモリリオーダリングはアウト・オブ・オーダー実行の一種であり、キャッシュメモリやメモリバンクといった異なるタイプのメモリのバスを最大限に有効活用するために利用される。
現在のほとんどのユニプロセッサのメモリ操作は、プログラムコードで指定された順番では実行されない。シングルスレッドのプログラムでは、すべてのアウト・オブ・オーダー実行はプログラマから隠され、すべての命令は順番通りに実行されたように見える。しかしながら、マルチスレッド環境(もしくはメモリバスで他のハードウェアと接続されている場合)では、問題が起こりえる。この場合、問題を避けるためにはメモリバリアを使わなければならない。
コンパイル時メモリオーダリング 編集
コンパイラはコンパイル時に、命令の実行順序を自由に入れ替えることができる。しかし、メモリアクセスの順番が重要な場合、問題が起きる。
ほとんどのプログラミング言語は、定義された順序で文を実行する実行スレッドの概念を持っています。従来のコンパイラは、高レベルの式を低レベルの命令列に変換し、機械レベルのプログラムカウンタに関連付けていた。
実行効果は2つのレベルで見ることができる。1つはプログラムコード内の高レベルで、もう1つは機械レベルで、他のスレッドや処理要素から見た並行プログラミングで、もう1つは機械状態にアクセスできるハードウェアデバッグ支援を使用したデバッグ時である(このサポートは、実行コアとは別に、機能的に独立した回路としてCPUやマイクロコントローラに直接組み込まれていることが多く、実行状態を静的に検査するためにコア自体が停止していても動作し続ける)。コンパイル時のメモリ順序は前者に関係するものであり、これらの他の見解には関係しない。
プログラム順序の一般的な問題 編集
式の評価によるプログラム順序の影響 編集
コンパイル時には、上位コードで指定されたものよりも細かい粒度のハードウェア命令が生成されることがある。手続き型プログラミングで観察できる主な効果は、名前の付いた変数に新しい値を割り当てることである。
sum = a + b + c; print(sum);
変数sumに代入する文の後にprint文が続いているので、print文が計算された変数sumを参照するときには、事前の実行シーケンスの観察可能な効果として、この結果を参照していることになる。プログラムシーケンスのルールで定義されているように、print関数コールがsumを参照するとき、sumの値は、変数sumに割り当てられた最も最近に実行されたもの(この場合、直前のステートメント)でなければならない。
マシンレベルでは、1つの命令で3つの数字を足すことができるマシンはほとんどないので、コンパイラはこの式を2つの加算演算に変換する必要がある。プログラム言語のセマンティクスにより、コンパイラが式を左から右の順に翻訳するように制限されている場合、生成されるコードはプログラマが元のプログラムに次のような文を書いたかのようになる。
sum = a + b; sum = sum + c;
コンパイラが加算の連想性を利用することを許可されている場合、代わりに次のようなコードが生成される。
sum = b + c; sum = a + sum;
コンパイラが加算の可換性を利用することを許可されている場合、代わりに次のように生成されるかもしれない。
sum = a + c; sum = sum + b;
ほとんどのプログラミング言語の整数データ型は、整数のオーバーフローがない場合に数学の整数の代数に従うだけであり、また、ほとんどのプログラミング言語で利用可能な浮動小数点データ型の浮動小数点演算は、丸め効果においては可換ではなく、表現の順序の影響が計算結果の小さな違いとして現れることに注意すべきである(ただし、最初の小さな違いは、長い計算の間に任意の大きな違いに連鎖する可能性がある)。
プログラマが整数のオーバーフローや浮動小数点の丸め効果を気にする場合は、同じプログラムを元のハイレベルで次のようにコード化することができる。
sum = a + b; sum = sum + c;
関数呼び出しによるプログラム順序の影響 編集
多くの言語は文の境界をシーケンスポイントとして扱い、次のステートメントが実行される前に、ある文のすべての効果が完了するように強制する。これにより、コンパイラは表現されたステートメント順に対応するコードを生成することになる。しかし、ステートメントはしばしばより複雑で、内部の関数呼び出しを含むことがある。
sum = f(a) + g(b) + h(c);
マシンレベルでは、関数を呼び出すには、通常、関数呼び出しのためのスタックフレームを設定する必要があり、これにはマシンメモリへの多くの読み取りと書き込みが含まれる。ほとんどのコンパイル言語では、コンパイラは都合の良いように関数呼び出しf、g、hの順序を自由に決めることができ、その結果、プログラムのメモリ順序が大規模に変更される。純粋な関数型言語では、関数呼び出しが目に見えるプログラムの状態(戻り値以外)に副作用を与えることは禁じられており、関数呼び出しの順序によるマシンメモリの順序の違いは、プログラムのセマンティクスにとって取るに足らないものとなる。手続き型言語では、呼び出された関数は、I/O操作の実行や、プログラムのグローバルスコープ内の変数の更新などの副作用を持つ可能性があり、いずれもプログラムモデルに目に見える効果をもたらす。
このような効果を気にするプログラマは、元のソースプログラムをより厳密に表現することができる。
sum = f(a); sum = sum + g(b); sum = sum + h(c);
ステートメントの境界がシーケンスポイントとして定義されているプログラミング言語では、関数呼び出しf、g、hが正確な順序で実行されなければならない。
メモリ順序の具体的な問題 編集
ポインタ表現によるプログラム順序の影響 編集
次にポインタをサポートするC/C++などの言語で、同じ加算をポインタ間接指定で表現した場合を考える。
sum = *a + *b + *c;
式 *x を評価することは、ポインタの「参照外し」と呼ばれ、x の現在の値で指定される場所のメモリを読み出すことになる。ポインタからの読み出しの効果は、アーキテクチャのメモリモデルによって決まる。標準的なプログラムの記憶装置から読み出す場合は、メモリの読み出し操作の順序による副作用はない。組込みシステムのプログラミングでは、メモリマップドI/Oが非常に一般的であり、メモリへの読み書きがI/O操作やプロセッサの動作モードの変更を引き起こすため、目に見える副作用が発生する。上の例では、ポインターが通常のプログラムメモリを指していて、このような副作用がないと仮定する。コンパイラは、これらの読み出しをプログラム順に自由に並べ替えることができ、プログラムから見える副作用はない。
もし代入された値がポインタ間接であったなら?
*sum = *a + *b + *c;
言語定義ではコンパイラがこれを次のように分解することはできそうにない。
// コンパイラによって書き換えられる // 一般的に禁止されている *sum = *a + *b; *sum = *sum + *c; となります。
これはほとんどの場合、効率的とは言えず、ポインタの書き込みには、目に見えるマシンの状態に副作用が生じる可能性がある。コンパイラはこの特別な分割変換を許可していないため、sumのメモリ位置への唯一の書き込みは、value式の3つのポインタ読み取りに論理的に従わなければならない。
しかしプログラマが整数オーバーフローの目に見えるセマンティクスを気にして、このステートメントをプログラムレベルで次のように分割したとする。
// プログラマーが直接作成したもの // エイリアシングを考慮して *sum = *a + *b; *sum = *sum + *c;
最初のステートメントは、2つのメモリ読み込みをエンコードしており、これらは*sumへの最初の書き込みの前に(どちらかの順序で)行わなければならない。2つ目のステートメントは、*sumの2回目の更新に先立って、2つのメモリ読み込みを(どちらかの順序で)エンコードする。これにより、2つの加算処理の順序が保証されるが、アドレスエイリアシングという新たな問題が発生する可能性がある。つまり、これらのポインタのいずれもが同じメモリ位置を参照する可能性がある。
例えば、この例では*cと*sumが同じメモリロケーションにエイリアスされていると仮定し、両方のバージョンのプログラムを、*sumが両方の代わりになるように書き換えてみる。
*sum = *a + *b + *sum;
これは何の問題もない。最初に*cと書いたものの元の値は*sumに代入された時点で失われ、*sumの元の値も失われるが、これは最初に上書きされたものなので、特に気にする必要はない。
// *cと*sumをエイリアスした場合のプログラムの内容 *sum = *a + *b; *sum = *sum + *sum;
*sumの元の値は最初のアクセスの前に上書きされ、代わりに次のような代数的な等価物が得られる。
// 上のエイリアスケースの代数的等価性 *sum = (*a + *b) + (*a + *b);
となり、文の並べ替えにより*sumには全く異なる値が代入されている。
ポインタ式はエイリアシングの影響を受ける可能性があるため、プログラムに目に見える影響を与えることなく再編成することは困難である。一般的なケースでは、エイリアシングの影響はないので、コードは以前のように正常に実行されているように見える。しかしエイリアシングが存在するエッジケースでは、深刻なプログラムエラーが発生する可能性がある。このようなエッジケースが通常の実行では全くないとしても、悪意のある者がエイリアシングが存在する入力を仕組んで、コンピュータ・セキュリティの悪用につながる可能性がある。
先ほどのプログラムを安全に並べ替えると以下のようになる。
// 適切な型の一時的なローカル変数'temp'を宣言する temp = *a + *b; *sum = temp + *c;
最後に、関数呼び出しを追加した間接的なケースを考えてみよう。
*sum = f(*a) + g(*b);
コンパイラは、*aと*bをどちらかの関数呼び出しの前に評価することも、*bの評価を関数呼び出しfの後まで延期することも、*aの評価を関数呼び出しgの後まで延期することもできる。もしfやgの実装に、ポインタaやbとのエイリアシングの対象となるポインタの書き込みという副作用が含まれている場合、3つの選択肢は、目に見えるプログラム効果が異なるものになる。
言語仕様におけるメモリ順序 編集
一般的に、コンパイルされた言語の仕様は、コンパイラがコンパイル時にどのポインタがエイリアスになる可能性があり、どのポインタがエイリアスにならないかを正式に判断できるほど詳細ではない。最も安全な方法は、コンパイラが常にすべてのポインタがエイリアスになる可能性があると仮定することである。このような保守的な悲観論は、エイリアスが存在しないという楽観的な仮定と比較して、恐ろしいほどのパフォーマンスを生み出す傾向がある。
その結果、C/C++などの多くの高級コンパイル言語では、最高のパフォーマンスを追求するためにコンパイラがコードの並べ替えで楽観的な仮定をすることが許される場合と、セマンティックな危険性を回避するためにコンパイラがコードの並べ替えで悲観的な仮定をすることが要求される場合について、複雑で洗練されたセマンティック仕様を持つようになった。
現代の手続き型言語では、メモリ書き込み操作が最大の副作用となるため、プログラムの順序セマンティクスを定義する際には、メモリ順序に関する規則が重要な要素となる。上記の関数呼び出しの順序変更は、別の検討事項のように見えるかもしれないが、これは通常、呼び出された関数の内部のメモリ効果と、関数呼び出しを生成する式のメモリ操作との相互作用に関する問題に発展する。
その他の困難と複雑さ 編集
as-ifでの最適化 編集
最近のコンパイラでは、さらに一歩進んで、目に見えるプログラムのセマンティクスに影響がなければ、どのような並べ替えでも(文をまたいでも)許されるというas-ifルールを採用している場合がある。このルールの下では、翻訳されたコード内の操作の順序は、指定されたプログラムの順序とは大きく異なる。エイリアスが実際に存在する場合(通常は、未定義の動作を示す不正なプログラムに分類される)に、エイリアスの重なりがない別々のポインタ式をコンパイラが楽観的に仮定することが許されている場合、積極的なコード最適化変換の悪影響は、コードの実行またはコードの直接検査の前には推測できない。未定義の動作とは、無限の可能性を秘めているのである。
コンパイラによる最適化の結果、セマンティクスが変更される可能性のある不正なプログラムを書かないように、言語仕様を確認するのはプログラマの責任である。システムプログラミング言語であるCやC++も同様である。
高級言語の中にはポインターを使わないものもあるが、これはプロのプログラマーであっても、このような注意深さや細部へのこだわりを確実に維持するのは難しいと考えられているからである。
メモリ順序のセマンティクスを完全に把握することは、この分野に精通している一部のプロのシステムプログラマにとっても、難解な専門分野であると考えられている。ほとんどのプログラマーは、自分のプログラミングの専門知識の範囲内で、これらの問題を十分に理解している。メモリ順序セマンティクスに特化した極端な例としては、コンカレント・コンピューティング・モデルをサポートするソフトウェア・フレームワークを作成するプログラマーが挙げられる。
ローカル変数のエイリアシング 編集
ローカル変数へのポインタが外部に漏れた場合、ローカル変数にエイリアシングがないとは言えないことに注意すべきである。
sum = f(&a) + g(a);
関数fが与えられたaへのポインタに対して何をしたかはわからない。関数gが後でアクセスするグローバルな状態にコピーを残しておくこともできる。最も単純なケースでは、fは変数aに新しい値を書き込み、この式は実行順に定義されないものとなる。fは、ポインタ引数の宣言にconst修飾子を適用することで、このような動作を目立たなくすることができ、この式は正しく定義される。このように、現代のC/C++の文化は、すべての実行可能なケースで関数の引数宣言にconst修飾子を与えることに、やや強迫観念的になっている。
C/C++では、fの内部が危険な手段としてconstness属性を型キャストすることを許可している。もしfが上の式を壊すような方法でこれを行うのであれば、そもそもポインタ引数の型をconstとして宣言すべきではない。
他の高級言語では、このような宣言属性は強力な保証となり、この保証を破るための抜け道が言語自体に用意されていないという傾向がある。アプリケーションが別のプログラミング言語で書かれたライブラリをリンクする場合、この言語の保証はすべて外れる(ただし、これはひどい悪意のある設計と考えられる)。
コンパイル時メモリバリアの実装 編集
これらのバリアは、コンパイラがコンパイル時に命令を入れ替えないように抑制する一方で、実行時のCPUによるリオーダリングを抑制することはできない。
- GNUインラインアセンブラ命令
asm volatile("" ::: "memory");
もしくは
__asm__ __volatile__ ("" ::: "memory");
は、GCCコンパイラが、その前後の読み書き命令を入れ替えることを禁止する。[1]
- Intel ECC compilerは"full compiler fence"な
__memory_barrier()
- Microsoft Visual C++コンパイラには
_ReadWriteBarrier()
が存在する。[4]
実行時メモリオーダリング 編集
SMPシステムの場合 編集
- 逐次一貫性(すべての読み込みと書き込みは順番通りに実行される)
- 緩い一貫性(いくつかのリオーダリングが許される)
- 読み込みが他の読み込みの後に並べ替えられる(キャッシュコヒーレンシやスケーラビリティのため)
- 読み込みが書き込みの後に並べ替えられる
- 書き込みが他の書き込みの後に並べ替えられる
- 書き込みが読み込みの後に並べ替えられる
- 弱い一貫性(明示的なメモリバリアによる制限を除けば、読み込みと書き込みの任意の並べ替えが可能)
いくつかのCPUでは、
- 読み書き命令があると不可分操作がリオーダするかもしれない。
- 一貫性のない命令キャッシュパイプラインがありえる。 その場合、命令キャッシュのフラッシュ/再読み込みといった特殊な命令なしには自己書き換えコードが動かない。
- 依存関係のあるデータ読み込みもリオーダするかもしれない(Alpha固有)。プロセッサがあるデータへのポインタを読み込んだときでも、そのポインタが指す正しいデータではなく、すでにキャッシュされてまだ無効になっていない古いデータをフェッチするかもしれない。この緩いリオーダリングを許すことで、ハードウェアはシンプルで高速になるが、読み込み側と書き込み側の両方でメモリバリアが必要になる。[5]
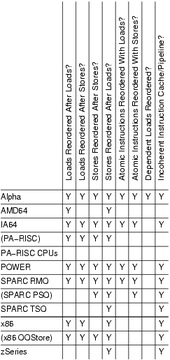
| 種類 | Alpha | ARMv7 | MIPS | RISC-V | PA-RISC | POWER | SPARC | x86 [注釈 1] | AMD64 | IA-64 | z | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WMO | TSO | RMO | PSO | TSO | ||||||||||
| ロードの後にロードを並び替えることができる | ◎ | ◎ | 実装依存 | ◎ | ✗ | ◎ | ◎ | ◎ | ✗ | ✗ | ✗ | ✗ | ◎ | ✗ |
| ストアの後にロードを並び替えることができる | ◎ | ◎ | ◎ | ✗ | ◎ | ◎ | ◎ | ✗ | ✗ | ✗ | ✗ | ◎ | ✗ | |
| ストアの後にストアを並び替えることができる | ◎ | ◎ | ◎ | ✗ | ◎ | ◎ | ◎ | ◎ | ✗ | ✗ | ✗ | ◎ | ✗ | |
| ロードの後にストアを並び替えることができる | ◎ | ◎ | ◎ | ◎ | ◎ | ◎ | ◎ | ◎ | ◎ | ◎ | ◎ | ◎ | ◎ | |
| アトミックはロードで並び替え可能 | ◎ | ◎ | ◎ | ✗ | ✗ | ◎ | ◎ | ✗ | ✗ | ✗ | ✗ | ◎ | ✗ | |
| アトミックはストアで並び替え可能 | ◎ | ◎ | ◎ | ✗ | ✗ | ◎ | ◎ | ◎ | ✗ | ✗ | ✗ | ◎ | ✗ | |
| 依存しあうロードは並び替え可能 | ◎ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | |
| インコヒーレントな命令キャッシュパイプライン | ◎ | ◎ | ◎ | ◎ | ✗ | ◎ | ◎ | ◎ | ◎ | ◎ | ✗ | ◎ | ✗ | |
- RISC-V メモリーオーダリングモデル
-
- WMO
- ウィークメモリーオーダー (デフォルト)
- TSO
- トータルストアオーダー (Ztsoエクステンションでのみサポート)
- SPARC メモリーオーダリングモデル
-
- TSO
- トータルストアオーダー (デフォルト)
- RMO
- 緩和型メモリーオーダー (最近のCPUではサポートされていない)
- PSO
- 部分メモリーオーダー (最近のCPUではサポートされていない)
脚注 編集
- ^ GCC compiler-gcc.h[リンク切れ]
- ^ ECC compiler-intel.h[リンク切れ]
- ^ Intel(R) C++ Compiler Intrinsics Reference
Creates a barrier across which the compiler will not schedule any data access instruction. The compiler may allocate local data in registers across a memory barrier, but not global data.
- ^ Visual C++ Language Reference _ReadWriteBarrier
- ^ Reordering on an Alpha processor by Kourosh Gharachorloo
- ^ Memory Ordering in Modern Microprocessors by Paul McKenney
- ^ Memory Barriers: a Hardware View for Software Hackers, Figure 5 on Page 16
- ^ Table 1. Summary of Memory Ordering, from "Memory Ordering in Modern Microprocessors, Part I"
{kind=link}
関連項目 編集
外部リンク 編集
- Computer Architecture — A quantitative approach. 4th edition. J Hennessy, D Patterson, 2007. Chapter 4.6
- Sarita V. Adve, Kourosh Gharachorloo, Shared Memory Consistency Models: A Tutorial[リンク切れ]
- Intel 64 Architecture Memory Ordering White Paper
- Memory ordering in Modern Microprocessors part 1
- Memory ordering in Modern Microprocessors part 2
- IA (Intel Architecture) Memory Ordering - YouTube - Google Tech Talk
この項目は、コンピュータに関連した書きかけの項目です。この項目を加筆・訂正などしてくださる協力者を求めています(PJ:コンピュータ/P:コンピュータ)。 |